I’ve been a Digital Content/Asset Manager for over 7 years professionally. But in reality most of us are content managers these days. Who isn’t taking pictures and videos with their phones that they want to share? It’s becoming necessary to educate ones self on some basic tenets of content management. But this is still a relatively new field, there’s some, but not a lot of resources and research done in this field, especially as every ones digital collections grow. The few resources I’ve found, are primarily marketing based, as are many of the jobs in this field. But from my perspective and professional experience, much of the practical content management comes in the form of technical IT and storage knowledge. Especially when working within even a small organization.
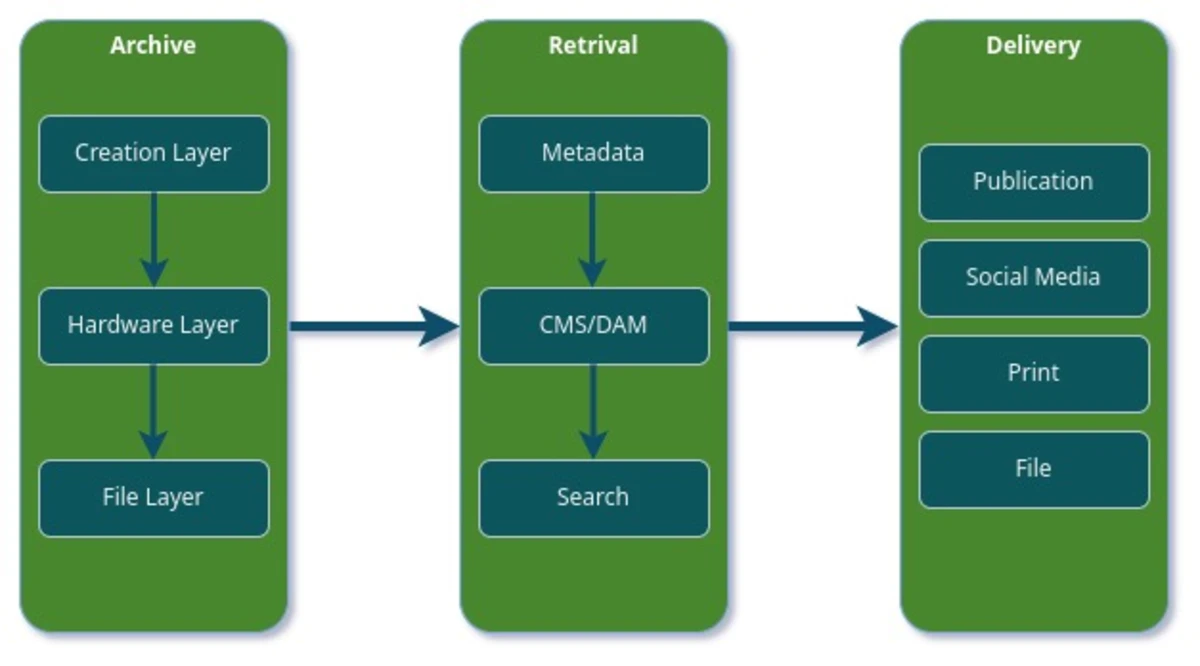
There’s a lot of steps between Creation and Delivery for anyone creating content. You have 3 basic layers for creation; beginning at; you guessed it,
- The Creation Layer. The making of content. Content can be anything. Video, audio, images, text files, etc. But you still need a place to keep it long term. That brings us to:
- The Hardware Layer. The place where you are digitally storing and backing up content. What happens when you need to find the content? This takes us to:
- The File Layer. Metadata management for any DAM system is crucial to being able to find the content you created.
These layers allow you to successfully implement what I think of as an Archive > Retrieval > Delivery cycle. What you do every time you look for content to post on social media, send to a friend, or send to an ad agency for a campaign or licensing agency, etc. Which is just like it sounds, the layers above work together create your Archive. When the need arises to deliver content, you need to Retrieve it; which is streamlined by inputting metadata, and of course our ultimate goal in whatever form it takes is the Delivery of the content.
If any one of the layers fails, the Archive > Retrieval > Delivery cycle falls apart. Without content you have no Archive. Without stable/efficient hardware and backups you can’t rely on your content being accessible or redundant in case of an eventual drive failure or data corruption. Without good metadata and keywords, you can’t retrieve your content effectively in the first place, thus making efficient delivery very difficult.
For instance a photographer could do a commercial shoot one day, and then the next they need to license an image to a magazine, then the day after that they’re sending a file to their printer for a fine art print, a student researcher might want to review a historical photographic process of which the photographer has examples of, all while they’re gathering and proofing images for a book to be published. Each of these tasks require every layer to be done effectively and efficiently. If any of the layers above are not up to par, the system grinds to a halt; and our ultimate goal of delivery in whatever form it takes, is very difficult and inefficient. These scenarios can be scaled to a painters or sculptors personal archive, a research archive, or even a museum.
There’s plenty more to this as well for effective content management, this is just the basics. I plan on diving into and expanding on the following additional considerations you may want to make; whether to utilize version control, if you need to adhere to any GDPR regulations or HIPAA compliance be sure to be aware of this before you start this process. You may also want to consider any workflow integrations you want to use, any user training that will be required for current staff, access control for privileged and unprivileged users, and security as well. Be sure to keep in mind scalability so your organization can grow, and most importantly costs, especially when it comes to maintenance and upgrades.
Photography (creation layer)
While lately I’ve been focused on Linux and storage, it all got sparked by my work as a photographer. I’ve been a photographer since I got my first camera from my grandfather when I was about 12. I ended up majoring in Photography, receiving a BFA in the medium before going on to work for a rather prolific photographer for 7 years. During my time there I managed both the digital and physical archive. This work showed me there’s much more to photography besides just taking pictures, especially today in this still largely uncharted realm of long term digital archiving and preservation. The content was endless, the clientele was high-profile, and deadlines were tight. Consumer grade solutions were quickly outgrown for this single photographer with an archive spanning decades.
Storage Administration & Backups (hardware layer)
As we all know content is king in todays world of social media. And as creators, we generate a MASSIVE amount of it! Whether it's video, photography files, or audio files for podcasts, we all need somewhere to store it. And while it's really easy to just leave everything on your laptop, it's a single point of failure. It can fail at any minute, and portable drives like those in a laptop are even more susceptible to drops and rough handling. SSDs also degrade and their storage cells can be corrupted over time. Nothing is safe! You might also outgrow this initial storage solution, and then what do you do?
Let’s say you do have a redundant local backup, and an offsite cloud backup, and plenty of storage for expansion but you still suffered the inevitable, you lost your main system and you need to restore your data. When’s the last time you tested your restore process? Let’s hope everything works!
This below command is a common one I use to sync directories. Dragging and dropping files through the GUI can be laggy as the computer needs to process everything graphical happening on the screen, in addition to everything going on under the hood and takes up processing power. So when working with large directories of tens of thousands of images it’s handy to know how to use the terminal. rsync is an amazing tool for copying files between local machines and over the network to remote machines. If desired, it can check at the block level for changes, but otherwise it checks size and modifcation time and updates accordingly, which is usually fine for my needs and saves processing power. If connection is dropped mid transfer, it picks up where it left off. You can use this in a cronjob too for a scheduled backup.
rsync -avP /Volumes/drive1/dir1/ /Volumes/drive2/dir1/
-a is for archive, it retains all the file permissions and other info; -v is for verbose output; and -P is for progress on the transfer.
If adding this to a cronjob, omit the -vP part of the flag as it won’t be necessary.
crontab -e
And have it scheduled to create a backup. This is true if the files aren’t being accessed/changed, as rsync works at the file level so be sure to run it at a time volumes won’t be in use, otherwise files that were changed mid-transfer will be corrupted.
Digital Content Management (file layer)
Once backups and restore procedures are in place (backups are easy, restores are what's important) you still need to of course organize the content and manage access to it.
It would make sense to create a folder structure that suits for your purposes, along with finding a DAM/CMS solution right for you and your team.
This isn’t a one-size-fits-all solution, there are lots of companies out there fighting for your money to use their product. You can research according to your needs. I prefer open source and am currently navigating and researching my own migration over to a full FOSS workflow from Adobe. I’ll be sure to share once I’ve accomplished it.
In the case of my folder structures; my RAW file uploads are organized into dated directories accompanied by a short description of place/event of the shoot, into a directory organized by year.
ALL_UPLOADS > 2023 > 2023-04-02(description)
Selects are made, and then RAW files are worked on. If you want to do everything inside something like Lightroom or another catalog oriented software, that works as long as it suits your needs. Once completed, I save a JPEG file into a categorized folder depending on my delivery needs. I tend to call my collection of digital imagery my “Archive”, even though the word archive has some very specific definitions, especially when discussing both digital backups and a physical archive, I can’t seem to find a better word for it. As creating what amounts to a “digital archive” is the ultimate goal.
From doing the above; you effectively have an archive, and to fulfill it’s purpose, whenever a request is recieved you’ll implement what amounts to an Archive > Retrieval > Delivery cycle, which is exactly as it sounds, but may take many shapes.
Archive > Retrieval > Delivery
Archive
I consider the long term storage of files as an archive. That includes keeping all the RAW files generated by whatever medium you work in, and their long term access.
Retrieval
Using the metadata and search constraints and keywords, depending on how detailed your file layer is, you’ll retrieve the material requested.
Delivery
Of course this lands us at delivery, the ultimate goal of why we create. Whether it’s a social media post, a print to make for someone, an image to send for an ad campaign, or a book to publish.
Finally, a conclusion.
While most of this is simply a by-product of creating, storing, and simply sending files to an intended recipient, it’s important to keep these concepts in mind as you create, store, and manage content. Thanks for following along this general overview of the content lifecycle, there are literal books on the subject so I intended to keep this as brief as I could. I plan on discussing effective backups and content management/keywording in future blogs, so stay tuned!
